Introduction to Data-to-Text Generation
Introduction to Data-to-Text Generation.
Introduction to Data-to-Text Generation
After wandering in the vast NLP research field for some time, I finally decided to work towards data-to-text generation in my PhD. In this blog, I’ll try to provide: a brief overview of the task’s requirements; some standard public datasets available; and the evaluation metrics used for measuring the performance on these datasets.
Natural Language Generation
First, I’ll start with a small introduction on Natural Language Generation (NLG). In NLG, the requirement is to generate a textual document (in some natural language) for the given input (in some format).
There are several real-world applications to automated text generation. Here are some examples.
 |
 |
Take the Medical Reporting domain for instance - suppose there’s a doctor who has to analyse the data from some patients different medical test results. The doctor will have to analyse each test’s result in order to make a decision on the patient’s condition. A summary of these test results in a textual format highlighting the main parts can be very benificial to the doctor and will reduce a lot of their time and effort required.
Take another example of Weather Forecasting - a textual report about the weather conditions summarising the huge numerical data can be very benificial for a meteorologist. Even for the general public, those reports can be very helpful in providing the weather information breifly.
Based on the input provided to the system, NLG can be broadly categorised into two different categories: first, text-to-text generation (T2T NLG); and second, data-to-text generation (D2T NLG).
T2T NLG
As the name suggests, in text-to-text generation, our goal is to generate text from unstructured textual input. For example, machine translation, where we take a text document in one natural language as input and produce the same content in different natural language as output.
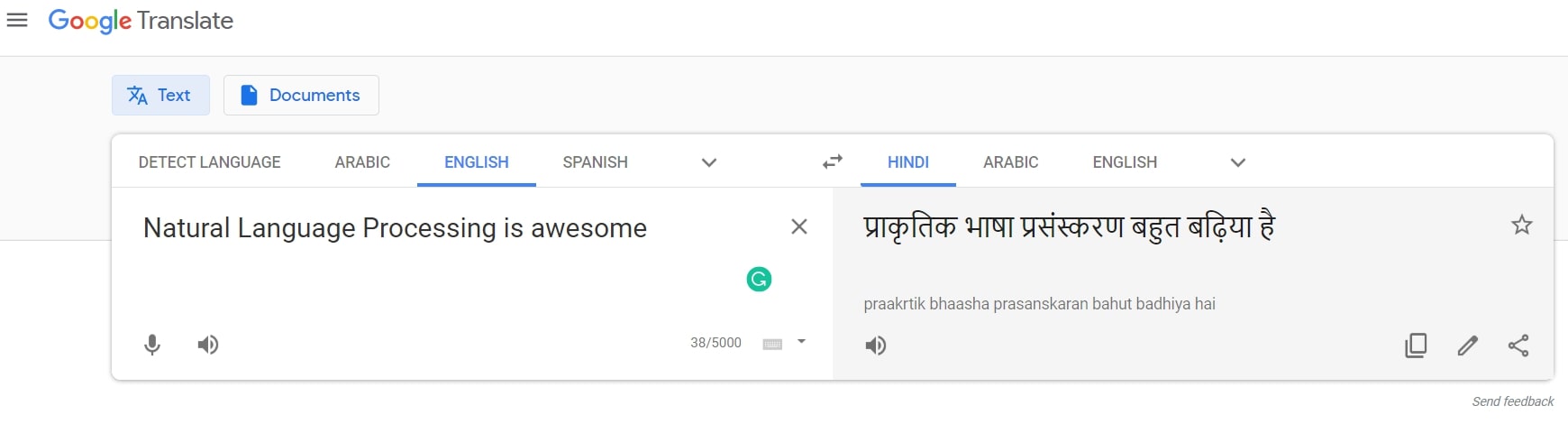
Text-to-Text Natural Language Generation (T2T NLG)
D2T NLG
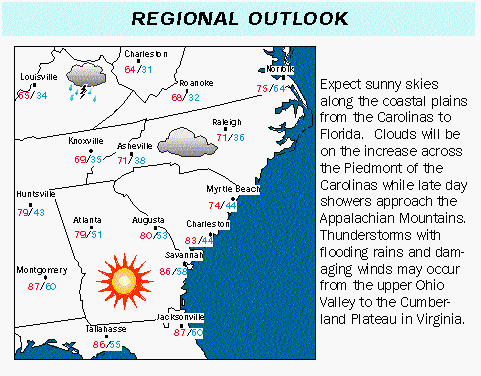
For data-to-text generation, the input is presented in a structured format, i.e., tablular, graphical or JSON format. With this structured input, we generate a textual output summarising the input values. For example, summarising NBA match where, for given box- and line-scores as input we have to generate a textual summary of the match as the output.

Data-to-Text Natural Language Generation (D2T NLG)
In general, automated text generation is challenging because grammar rules are very complex, and also, there can be several meaning to same words in different context.
Even after we develop an automated system for text generation, it is challenging to automatically evaluate the texts generated from that system. Unlike most supervised problems, there’s no class knowledge in form of labels to evaluate the performance. Here the system’s goal is to generate accurate, fluent; and diverse texts, not just predicting some label like in most of the other NLP tasks.
Subtasks in D2T NLG
Data-to-Text generation is a long process. It invovles a lot of things - selecting important insights from the data to finally generating the textual document summarising that data. In general, the whole pipeline of D2T can be broadly categorised into these different subtasks:
-
Content Determination: deciding which information from the input will be included in the final text;
-
Text Structuring: select the ordering of the selected information in the final text output;
-
Sentence Aggregation: selecting which information to be presented in a separate sentence and which two (or more) information can be presented in the same sentence;
-
Lexicalisation: finding the correct words and phrases to express the information in a sentence;
-
Referring Expression Generation: selecting domain-specific words and phrases; and
-
Realisation: Combining all the words and phrases into well-formed sentences.
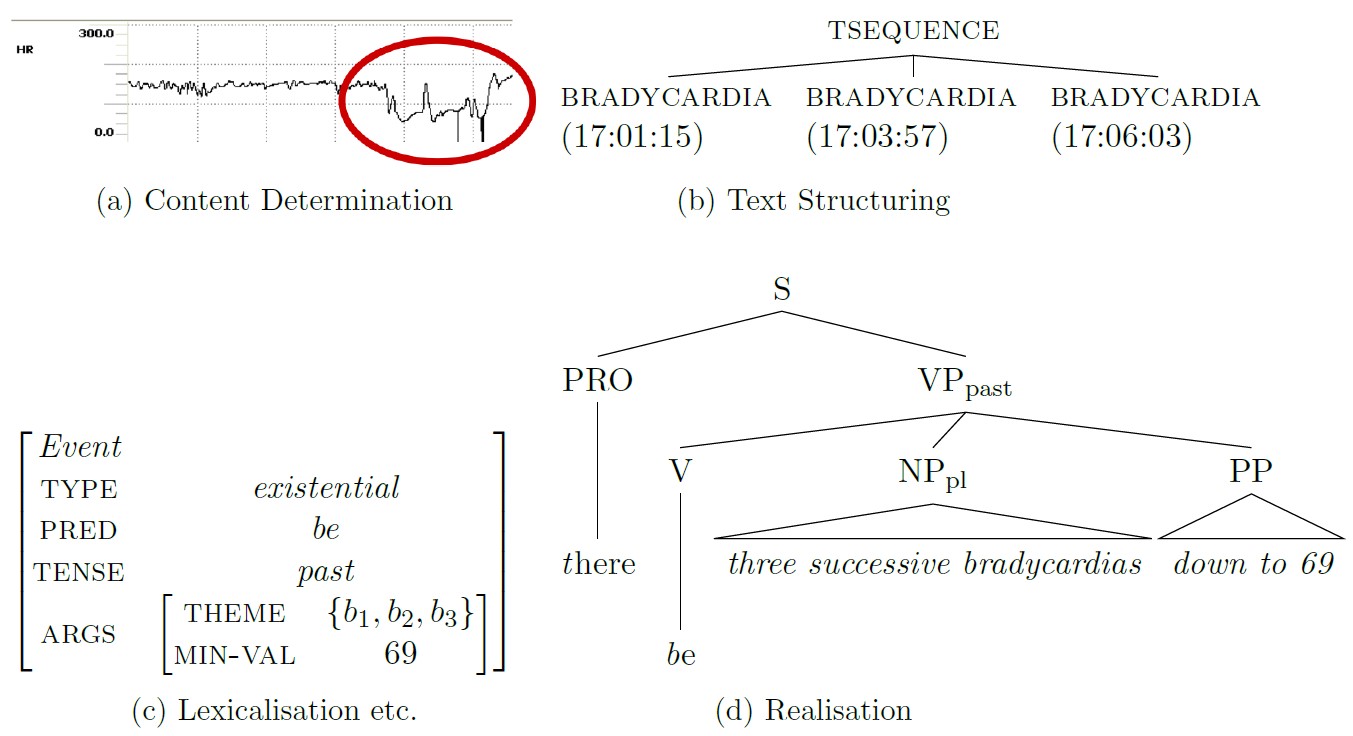
Let’s discuss these subtasks with an example. The figure below illustrates a simplified example from the neonatal intensive care domain.
 |
|---|
| The tasks that needs to be performed in order to generate the full textual summary from the input data can be described as follows: first the system has to decide what the important events are in the data (a, content determination), in this case, occurrences of low heart rate (bradycardias); then it has to decide in which order it wants to present data to the reader (b, text structuring) and how to express these in individual sentence plans (c, aggregation; lexicalisation; reference); finally, the resulting sentences are generated (d, linguistic realisation). |
Subtasks in D2T NLG (source)
The specification of these subtasks vary from domain to domain, but the basic idea remains the same.
Let’s take another example, the NBA match summarisation (the D2T NLG figure shown above) for instance. Here also, the generation will happen in the following steps:
- first, we need to decide what records from the input table will be dispalyed in the final text (or what to say?);
- second, we’ll have to decide in what order those records will be displayed, which will also include the deciding on which records will have separate senetences and which ones will be included in the same sentence (or how to say?); and
- finally, generating the text by combining all the decisions made in previous steps (or saying what’s decided).
Public Datasets and Evaluation Metrics
Now that we know about the expectations in D2T NLG, let’s see some of the standard datasets available in public domain and evaluation metrics used to measure the performance of different methods on these datasets.
To keep track of the state-of-the-art in this field, I would recommend to follow this article on NLP-progress or this task category on Papers with Code.
RotoWire
The dataset consists of articles summarizing NBA basketball games, paired with their corresponding box- and line-score tables. It is professionally written, medium length game summaries targeted at fantasy basketball fans. The writing is colloquial, but structured, and targets an audience primarily interested in game statistics. The picture used above for the example of D2T NLG is from this dataset only.
The performance is evaluated on two different automated metrics: first, BLEU score; and second, a family of Extractive Evaluations (EE). EE contains three different submetrics evaluating three different aspects of the generation. Since EE metrics are comparatively new than others, I’ll briefly explain them here:
-
Content Selection (CS): precision (P%) and recall (R%) of unique relations extracted from generated text that are also extracted from golden text. This measures how well the generated document matches the gold document in terms of selecting which records to generate.
-
Relation Generation (RG): precision (P%) and number of unique relations (#) extracted from generated text that also appear in structured input provided. This measures how well the system is able to generate text containing factual (i.e., correct) records.
-
Content Ordering (CO): normalized Damerau-Levenshtein Distance (DLD%) between the sequences of records extracted from golden text and that extracted from generated text. This measures how well the system orders the records it chooses to discuss.
I am not explaining other evaluation metrics here, I’ll try to do that in some later post.
WebNLG
The WebNLG challenge consists in mapping data to text. The training data consists of Data/Text pairs where the data is a set of triples extracted from DBpedia and the text is a verbalisation of these triples. For example, given the three DBpedia triples (as shown in [a]), the aim is to generate a text (as shown in [b]):
-
[a]. (John_E_Blaha birthDate 1942_08_26) (John_E_Blaha birthPlace San_Antonio) (John_E_Blaha occupation Fighter_pilot)
-
[b]. John E Blaha, born in San Antonio on 1942-08-26, worked as a fighter pilot.
The performance is evaluated on the basis of BLEU, METEOR and TER scores. The data from WebNLG Challenge 2017 can be downloaded here.
Meaning Representations
The dataset was first provided for the E2E Challenge in 2017. It is a crowd-sourced data set of 50k instances in the restaurant domain.Each instance consist of a dialogue act-based meaning representations (MR) and up to 5 references in natural language (NL). For example:
-
MR: name[The Eagle], eatType[coffee shop], food[French], priceRange[moderate], customerRating[3/5], area[riverside], kidsFriendly[yes], near[Burger King]
-
NL: “The three star coffee shop, The Eagle, gives families a mid-priced dining experience featuring a variety of wines and cheeses. Find The Eagle near Burger King.”
The performance is evaluated using BLEU, NIST, METEOR, ROUGE-L, CIDEr scores. The data from E2E Challenge 2017 can be downloaded here.
Further Steps
- For a detailed review of the field, I would recommed reading this survey paper.
- Here you can find a list of public datasets available for D2T NLG.
- Have a look at the ACL’s Special Interest Group on Natural Language Generation - ACL SIGGEN.
- Would recommend to follow Prof. Ehud Reiter’s Blog, he writes a lot on the issues of NLG (alsow w/ ML/DL) research.